

You’re trying to understand what Is Recall In Machine Learning. Recall is a metric that tells you exactly that, focusing on identifying true positives. This article will guide you through understanding what is recall In machine learning; from its definition to practical applications like medical diagnostics and fraud detection.
Stay tuned for insights into boosting your model’s performance.
Here are other blog posts about Machine Learning and AI that could help you:
- What is a Key Differentiator of Conversational AI?
- The Truth Revealed: Can Turnitin Detect ChatGPT in 2024?
Key Takeaways
- Recall in machine learning is about finding all the true positives, like catching all cases of a disease or spotting fraud. It’s like making sure you find every lost sock.
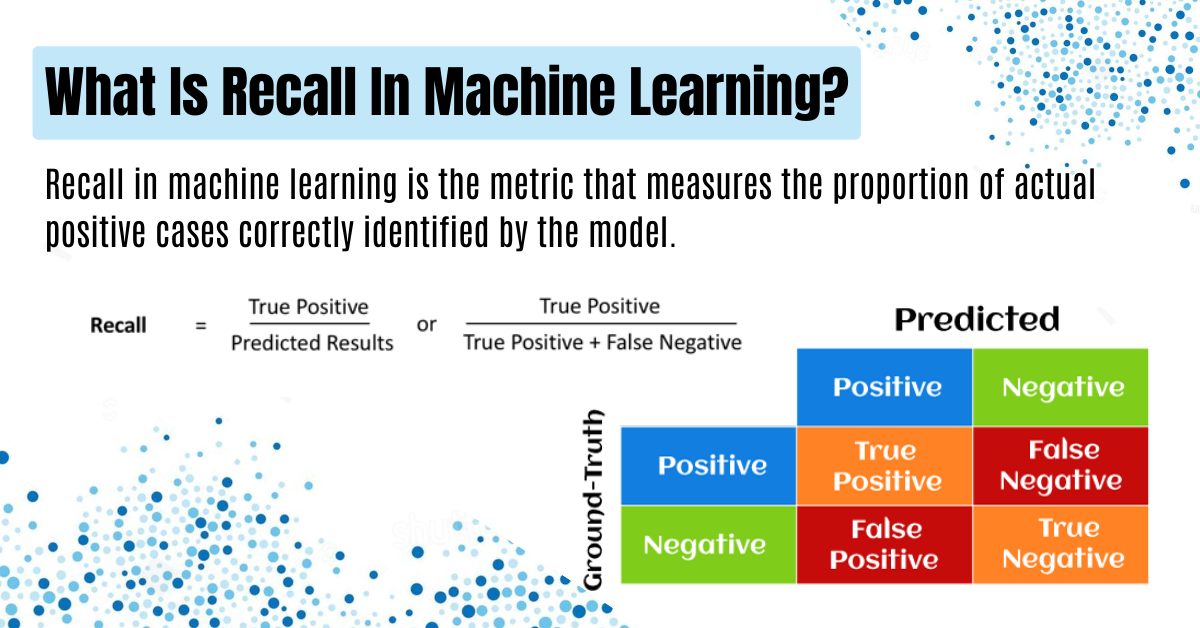
- The formula for recall helps us understand how well our model identifies everything it should. It shows the percentage of correct identifications out of all that are actual and divides it by the sum of true positives and false negatives.
- High recall is super important in areas where missing something could be bad, such as medical tests for diseases or detecting fraud in banking. Even if we get some wrong (false positives), catching as much as possible can save lives or prevent financial loss.
- To improve recall, using synthetic data and tweaking algorithms can help, especially with imbalanced data where some things happen rarely. This makes sure we don’t miss out on detecting rare but serious events.
- There’s a balance between precision (getting things right) and recall (finding everything that needs to be found). Depending on what’s more important – avoiding false alarms or not missing anything – we might choose to focus on one more than the other. In healthcare, finding nearly all conditions matters most; in emails, not mislabeling good emails as spam might be key.
Table of Contents
Defining Recall in Machine Learning
Recall in machine learning measures the ability of a model to identify all relevant instances within a dataset. It’s particularly important when avoiding false negatives is crucial, such as in medical diagnoses or fraud detection systems.
Conceptual Explanation
Think of recall in machine learning like finding all the lost socks in your laundry. It’s about making sure you get every single one, not just some. Recall measures how good a model is at spotting these “lost socks” — or in machine science speak, the true positives.
True positives are the items we correctly identify as correct out of all possible correct choices.
Recall tells us how many of the actual positives our model catches.
A simple way to see it is with sick people and a medical test. If 100 people are sick, and the test finds 90 of them, the recall rate is 90%. Here, sensitivity or true positive rate comes into play.
It shows us how sensitive our test is to picking up on everyone who truly has what we’re testing for. By focusing on how many right answers we find (true positives) versus those we miss (false negatives), recall gives us a clear picture of effectiveness without getting tangled up in extra details that don’t pertain to our main goal: identifying all relevant cases accurately.
Mathematical Formula
Moving on from what is recall in machine learning, let’s talk about how you figure it out. The formula for recall is like a recipe that tells you exactly what to mix. You take the number of true positives (TP) and divide it by the sum of true positives and false negatives (FN).
What does this look like in real life? Say your machine learning model is a doctor testing for sickness. If it finds 11 sick people out of 100 correctly, its recall is 0.11 or 11%.
This means it correctly identified 11% of all sick patients.
To use this formula, keep in mind two things: True Positives are when the model guesses right, and False Negatives are when the model misses something important. So, Recall = TP / (TP + FN) tells you how good your model is at catching everything it should.
It’s key in making sure models don’t overlook important cases, like finding diseases in medical tests or spotting frauds in bank transactions.
Importance of Recall in Machine Learning Models
What is recall in machine learning? Recall is crucial in machine learning models, especially in sensitive areas like medical diagnostics and fraud detection systems. It ensures that serious issues are not overlooked, making it a vital performance metric.

Significance in Medical Diagnostics
In medical diagnostics, catching as many positive cases as possible is key. Think about it. If a doctor uses a machine learning model to find malignant tumors and this model has a recall of 0.11, that means it finds about 11 out of every 100 real tumors.
This is critical because missing tumors could mean not treating a patient who really needs help. So, in medicine, high recall helps doctors identify almost all patients with a condition without letting many slip through the cracks.
For example, if you’re looking at heart disease prediction models, you want them to alert for potential heart issues more often than not. Even though some alerts might be false alarms, the cost of missing an actual case of heart disease is far too high.
That’s why in fields like healthcare where lives are on the line, making sure your predictive modeling catches as many true positives as possible matters most—it can literally save lives by ensuring no serious condition goes unnoticed.
Role in Fraud Detection Systems
In fraud detection, recall plays a crucial role. It helps in catching fraudulent activities and reducing financial losses by ensuring that potential risks are flagged. High recall is especially important in fraud detection systems as it minimizes false negatives, making certain that fraudulent transactions don’t go unnoticed.
For instance, consider an online payment system where high recall can ensure that any potentially fraudulent transaction is detected early on and stopped before causing financial harm.
In the realm of fraud detection systems, prioritizing high recall helps to safeguard against possible losses due to undetected fraudulent activities. This underlines the significance of recall in efficiently identifying and preventing financial fraud.
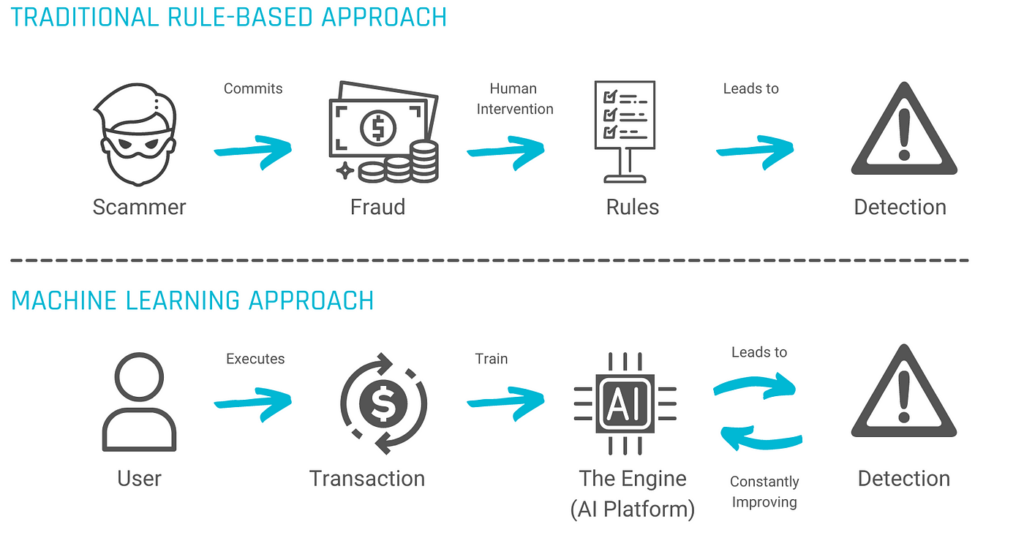
Source: Medium | Fraud Detection with Machine Learning — A Use Case
Comparing Recall with Other Performance Metrics
In machine learning, recall is a vital metric for evaluating the performance of classification models. However, comparing it with other metrics like precision and accuracy provides a more comprehensive understanding of a model’s effectiveness. So let’s compare what is recall in machine learning with other important metrics.
Recall vs. Precision
Precision measures the proportion of correct positive identifications out of all positive identifications made… Recall, on the other hand, measures the proportion of actual positives that are correctly identified.
The main distinction is that precision focuses on minimizing false positives, while recall aims at reducing false negatives. For example in medical diagnostics, high precision would mean fewer patients being wrongly diagnosed with a disease they don’t have…
High recall would mean ensuring that no patients with an actual disease are missed during diagnosis.
Recall vs. Accuracy
Recall and accuracy are both measures of how well a model can predict outcomes. Accuracy looks at the overall correctness of predictions, while recall focuses on identifying true positives specifically.
Imagine you’re looking for all the red marbles in a bag – recall measures how many of them you found compared to how many were actually there, whereas accuracy considers not just the red marbles but all the marbles in total.
When it comes to medical diagnoses or fraud detection, you want high recall as missing out on an actual ailment or failing to catch a fraudulent activity is risky. On the other hand, in tasks where precision is more crucial than inclusivity, such as spam email filtering, precision may be prioritized over recall.
The F1 Score and Its Relevance
To know what is recall in machine learning, there are other factors you should consider.
The F1 score is a significant metric in evaluating the performance of classification models. It balances the trade-off between precision and recall. This means it provides a single value that takes into account both false positives and false negatives, making it useful for comparing different models.
For instance, if you have an imbalanced dataset with more negative examples than positive ones, the F1 score becomes crucial as it considers both types of errors equally.
It also plays a crucial role when decision-makers prioritize balanced performance over specific needs like high precision or recall. Understanding the relevance of the F1 score helps in making informed decisions related to model selection and assessing its effectiveness in various contexts.

Impact of Imbalanced Data on Recall
Imbalanced data can lead to skewed recall results, affecting the ability of a machine learning model to accurately identify certain classes. This is particularly crucial in fields like medical diagnostics and fraud detection where accurate classification of events is paramount.
Strategies to Manage Imbalanced Data
To manage imbalanced data in machine learning, you can consider the following strategies:
- Resampling Techniques:
- Oversampling the minority class by replicating instances.
- Undersampling the majority class by removing instances.
- Synthetic Data Generation:
- Using algorithms like SMOTE to create synthetic data for the minority class.
- Ensemble Methods:
- Employing ensemble techniques such as bagging and boosting to balance class distribution.
- Cost-Sensitive Learning:
- Adjusting the misclassification costs to give more importance to the minority class.
- Algorithmic Adjustments:
- Modifying algorithms with weighted loss functions to focus on improving recall for minority class instances.
- Utilizing Anomaly Detection:
- Identifying and treating rare instances as anomalies, thus improving recall performance.
These strategies can help address imbalanced data challenges and enhance the performance of machine learning models, especially in scenarios where certain classes are underrepresented.

Advanced Techniques to Improve Recall
To boost recall, using synthetic data can help. Also, adjusting algorithms for better recall is crucial.
Utilizing Synthetic Data
Balancing imbalanced datasets is important in machine learning. Synthetic data can help with that by creating more instances of the minority classes. This improves recall and ensures that the model doesn’t overlook important information.
By using synthetic data, you can enhance your machine learning model’s performance, especially when dealing with imbalanced data. This means better accuracy in predicting rare events such as fraud detection or medical diagnoses.
Algorithmic Adjustments for Better Recall
To improve recall, you can make algorithmic adjustments. Here are some techniques to achieve better recall:
- Fine-tuning the thresholds for classification scores to prioritize minimizing false negatives.
- Applying ensemble methods such as bagging and boosting to strengthen the model’s ability to capture minority class instances.
- Leveraging cost-sensitive learning algorithms that assign higher costs to misclassifying the minority class.
- Employing outlier detection techniques to identify and handle rare instances more effectively.
- Implementing transfer learning by utilizing pre-trained models as a starting point for training on related tasks.
These adjustments can help your machine learning model achieve better recall performance, particularly in scenarios with imbalanced data distributions or where identifying all positive instances is critical.

Precision-Recall Trade-off
Understanding the Compromise
When you want to prioritize recall over precision – and vice versa.
Understanding the Compromise
When balancing precision and recall, you face a trade-off. If you increase one, the other decreases. This compromise is crucial in making decisions about setting the boundary for classifying something as positive or negative.
For example, in medical diagnostics, setting too high of a boundary could mean missing some real cases – that’s lower recall but higher precision. And if you set it too low, you might catch more legitimate cases but also falsely identify more non-cases – that’s higher recall but lower precision.
The choice between precision and recall depends on your specific goal: are false positives costlier than false negatives? Identifying this balance is vital for effective decision-making in various fields like healthcare and finance where model performance carries significant weight.
When to Prioritize Recall Over Precision
When making critical decisions, prioritizing recall over precision is vital in situations where missing positive cases could have severe consequences. For instance, in medical diagnostics, it’s more important to catch all possible cases of a disease, even if it means some false alarms.
Similarly, in fraud detection systems, it’s crucial to identify every potential fraudulent activity, balancing slightly higher false positives for thoroughness. These scenarios underscore the significance of recall in ensuring comprehensive coverage and minimizing risks associated with missed positive instances.
In areas where capturing all relevant data holds significant value such as identifying diseases or detecting frauds – prioritizing recall proves essential to avoid overlooking critical cases that could have severe implications if not captured accurately.
Practical Examples of Recall in Action
Are you ready for some real-life examples of recall in action? Let’s look at how it plays out in financial services and healthcare.
Case Study in Financial Services
In financial services, a high recall is crucial for identifying potentially fraudulent transactions. Let’s say, for example, that in a bank’s fraud detection system, the model has a high recall rate.
This means it can accurately flag more fraudulent activities among the numerous legitimate transactions. As a result, this helps minimize financial losses and strengthens security measures within the banking system.
For instance, consider XYZ Bank that utilizes machine learning algorithms to detect fraud in credit card transactions. By achieving a high recall rate in their model, they can accurately identify and block suspicious activities with less chance of missing any potential threats among genuine transactions.

Case Study in Health Care
In the health care sector, a high level of recall is crucial for effectively identifying diseases or medical conditions. For instance, in cancer diagnosis, a model with high recall will ensure that most malignant cases are detected correctly, which is vital for timely treatment and improved patient outcomes.
This high recall can significantly reduce the instances of false negatives – cases where the condition is present but not identified by the model.
Consider an example of using machine learning algorithms to detect rare but severe medical conditions such as sepsis or heart conditions based on various patient metrics like heart rate variability and blood pressure.
Here, high recall would help in accurately classifying positive cases (true positives) even if they are very few compared to negative ones (false negatives). Such accurate identification allows for prompt intervention and improves overall patient care.
Moreover, when deployed in electronic health records systems or telemedicine platforms, models with high recall rates contribute to more reliable diagnostics helping physicians make informed decisions about patient’s treatment pathways.
Conclusion – What Is Recall In Machine Learning?
Understanding recall in machine learning is crucial for assessing the performance of your models. It measures the ability of a model to identify all relevant cases within a dataset.
By striking a balance between precision and recall, you ensure that your model both minimizes false positives and captures as many positive cases as possible.
You can visualize this trade-off using the classification threshold, adjusting it to impact precision and recall values. Additionally, various metrics like the F1 score consider both precision and recall in machine learning evaluation.
Remember that high recall is vital in medical diagnosis to catch as many positive cases as possible, while high precision matters more in financial fraud detection to minimize false positives.
Knowing when to prioritize one metric over the other for specific tasks is essential for effectively evaluating machine learning models. Keep these insights in mind as you continue your journey into machine learning!
FAQs – What Is Recall In Machine Learning?
1. What is recall in machine learning and why is it important?
Recall, a key classification metric in machine learning, helps evaluate binary classifiers by measuring the true positive rate against false negatives. It’s crucial for model evaluation and bias-variance analysis.
2. How do you calculate recall?
The recall formula involves dividing the number of true positives by the sum of true positives and false negatives. In essence, it shows how well your binary classifier identifies positive tests correctly.
3. What’s the difference between recall vs precision?
While both are used to measure supervised classification effectiveness, they serve different purposes… Precision focuses on minimizing Type I errors (false positives), while Recall aims at reducing Type II errors (false negatives).
4. Can you explain ROC curve and Area Under The Curve (AUC)?
Sure! The ROC curve – short for Receiver Operating Characteristic curve – plots sensitivity versus 1-specificity for binary classifiers… The area under this ROC curve measures overall performance across all thresholds, with higher values indicating better performance.
5. How does recall relate to other metrics like F-score or Matthews Correlation Coefficient?
Recall along with precision forms part of several composite metrics such as F-score – a weighted harmonic mean of these two; or Matthews Correlation Coefficient that takes into account all four elements of confusion matrix: True Positives, False Positives, True Negatives, False Negatives…
6. Are there any specific applications where high recall is especially important?
Yes indeed! High Recall plays a critical role in recommender systems where missing out on potential recommendations could be costly… Similarly in medical testing scenarios – higher Recall minimizes chances of missed diagnoses which can have serious implications.


