

What is Tokenization in NLP?
Have you ever felt overwhelmed trying to understand how machines process human language? So you want to know what is tokenization in NLP.
Tokenization is a key step in natural language processing (NLP) that breaks down text into manageable pieces. This blog post will guide you through the what, why, and how of tokenization in NLP, including its types, examples, and tools. Get ready to simplify text processing!
Table of Contents
Introduction – What is Tokenization in NLP?
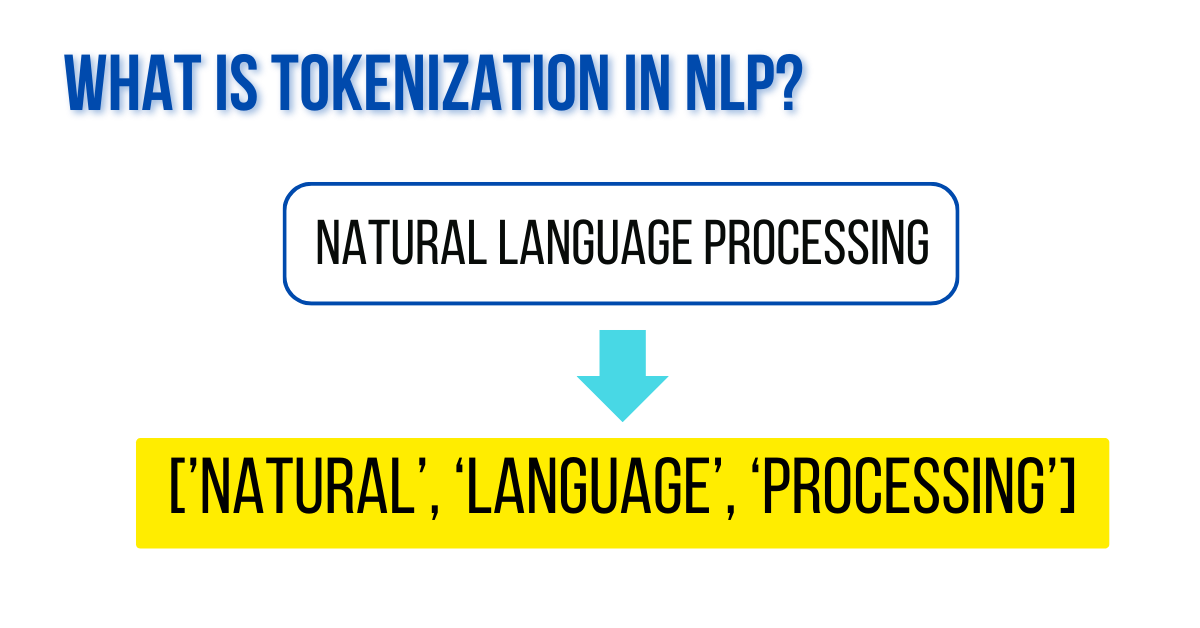
Tokenization in NLP is like chopping a long string of words into smaller, digestible pieces, so machines can understand and process them. It’s a crucial step in NLP that helps in breaking down unstructured text into manageable units called tokens.
Understanding tokenization is essential for anyone diving into the world of NLP. It not only makes text processing easier, but also lays the foundation for various NLP tasks like sentiment analysis and text classification.
Let’s explore the different types, examples, and tools for tokenization in NLP to get a better grasp of this fundamental concept.
Key Takeaways
- Tokenization in NLP splits text into smaller units like words, sentences, or characters. This helps machines understand and process human language.
- There are several types of tokenization: word, sentence, subword (such as Byte Pair Encoding), and character. Each serves a different purpose in NLP.
- Python libraries like NLTK, spaCy, and Hugging Face Tokenizers provide powerful tools for text tokenization to make natural language processing tasks easier.
- Challenges in tokenization include language-specific issues, handling punctuation and special characters correctly, and understanding the context of tokens for accurate processing.
- Proper tokenization is critical for successful machine learning projects that involve natural language understanding such as sentiment analysis or text classification.
What is Tokenization in NLP?
Tokenization in NLP breaks text into smaller units for processing. It includes word, sentence, subword, and character types.
Definition of Tokenization
Tokenization in NLP splits your text into smaller chunks, or tokens. Think of it as cutting sentences into words or pieces that make more sense to computers. It’s like chopping a long string of words so machines can easily digest and understand them.
This step is super important for tasks such as language understanding, text analysis, and data processing in NLP. Every word matters in understanding the big picture.
This process deals with different types of tokens – words, characters, or subwords (parts of words). Each type has its own way of breaking down text to help machines grasp what’s being said or written. By turning large chunks of text into manageable pieces, tokenization lays the groundwork for further NLP tasks like sentiment analysis and machine learning projects aimed at making sense of human language.
Purpose of Tokenization
Tokenization serves an important role in NLP. It assists in breaking down unstructured data and natural language text into smaller units or tokens, such as words, characters, or subwords.
By doing so, tokenization makes it simpler for machines to process and analyze the text. This is crucial for tasks like text mining, linguistic analysis, and information retrieval.
For example, when dealing with a sentence or phrase, tokenization helps split it into manageable chunks called tokens. These tokens can then be analyzed more effectively by machines. This structured representation of text underpins various NLP tasks including sentiment analysis and language modeling. Moreover, tools like NLTK and spaCy are designed to enhance the efficiency of this process through their built-in libraries for tokenization in Python – making them invaluable resources for navigating complexities in the realm of data processing.

Types of Tokenization
Tokenization in NLP involves breaking unstructured data into smaller, manageable units. There are different types of tokenization used in NLP to achieve this goal:
Word Tokenization
Divides text into words, separating by spaces and punctuation.
Example: “The quick brown fox” is tokenized into [“The”, “quick”, “brown”, “fox”].
Word tokenization involves breaking down a sentence or paragraph into individual words. For example, the sentence “Tokenization is crucial in NLP” would be split into tokens such as “Tokenization,” “is,” “crucial,” “in,” and “NLP.” This process allows machines to understand and process each word separately, making it easier for them to analyze and work with the text.
When dealing with word tokenization, it’s important to note that punctuation marks are often treated as separate tokens. For instance, in the phrase “Hello, World!”, both “Hello” and “,” would be considered as individual tokens. This step is essential for various natural language processing tasks like text classification and sentiment analysis since it lays the groundwork for further analysis of the text data.
Sentence Tokenization
Splits text into individual sentences based on punctuation marks like periods, exclamation points, and question marks.
Example: “This is a sentence. This is another.” is tokenized into [“This is a sentence.”, “This is another.”].
Sentence tokenization is a vital part of natural language processing. It involves splitting paragraphs and sentences into smaller units, called tokens. These tokens are usually the individual sentences themselves.
The significance of sentence tokenization lies in its ability to provide a structured representation of text. This makes it easier for machines to process and analyze different sections of the text separately, enhancing data analysis and computational linguistics tasks.
Keep this in mind while utilizing tools for tokenization such as NLTK, spaCy, or Hugging Face Tokenizers to make your data preprocessing more effective in NLP tasks like text classification or sentiment analysis!

Subword Tokenization
Breaks down words into subword units, useful for languages with complex word structures or when dealing with rare words.
This involves breaking down words into smaller meaningful units to address complex word structures and morphologically rich languages.
- Byte Pair Encoding (BPE): This method merges the most frequent pair of consecutive symbols iteratively, allowing for the creation of a vocabulary that represents all words in a given language.
- SentencePiece: It is designed to handle large-scale data efficiently and supports various models like unigram, BPE, and word.
- WordPiece: This subword tokenization algorithm is similar to BPE but introduces a mechanism to limit the size of the resulting vocabulary.
- Unigram Language Model: It uses a simple heuristic based on frequency information to segment text into subword units, making it particularly suitable for agglutinative languages or domains with specific terminologies.
These subword tokenization techniques are crucial tools in NLP for handling the complexities of word structures across various languages and
Character Tokenization
Represents the text as individual characters instead of words or subwords.
Example: “Text” would be tokenized into [“T”, “e”, “x”, “t”].
These types of tokenization are essential for processing natural language text effectively because they provide structured representations that can be easily handled by machines in NLP tasks.
Character tokenization involves breaking down text into individual characters. This means that each letter, number, punctuation mark, or symbol becomes a separate token.
For instance, in the word “apple,” the tokens would be ‘a’, ‘p’, ‘p’, ‘l’, ‘e’. Character tokenization provides a more granular view of the text and can be useful for certain language processing tasks.
For NLP purposes, character tokenization allows machines to process text at a very fine-grained level. By representing each character as an individual unit, NLP models can capture detailed patterns and structures within the language data.
This type of tokenization is particularly valuable when dealing with languages that have complex word structures or when analyzing texts where understanding at the character level is crucial. This approach significantly underpins various language processing tasks such as sentiment analysis and named-entity recognition as it enables the model to work with text on a highly detailed level.

Tools and Libraries for Tokenization in Python
Python offers a range of powerful tools and libraries for tokenization, enabling you to efficiently process natural language data. These resources allow seamless tokenization with easy integration into your NLP projects.
NLTK
NLTK, or Natural Language Toolkit, is a powerful library for tokenization in Python. It offers various tools and resources to process human language data. With NLTK, you can effortlessly tokenize text into words or sentences.
This toolkit also provides functionalities for stemming, tagging parts of speech, and parsing syntax.
NLTK empowers you with the ability to handle text data effectively by breaking it down into smaller units called tokens. You can utilize its capabilities to perform tasks like text classification and sentiment analysis seamlessly.
Additionally, NLTK is equipped with diverse corpora and lexical resources that support several NLP operations. Whether it’s word segmentation or sentence splitting, NLTK stands as a reliable resource for your NLP endeavors.
spaCy
When it comes to NLP toolkit, spaCy is a powerful and widely-used library for tokenization. It not only provides efficient tokenization but also offers capabilities such as part-of-speech tagging, named entity recognition, and dependency parsing.
With its user-friendly interface and detailed documentation, spaCy is a great tool for diving into the world of natural language processing.
Hugging Face Tokenizers
Hugging Face Tokenizers offer powerful tools for natural language processing (NLP) in Python. With these tokenizers, you can efficiently prepare textual data for analysis and modeling.
These tools provide various tokenization methods, such as byte-level BPE and WordPiece, which are instrumental in breaking down text into meaningful components.
You’ll find that the Hugging Face Tokenizers add value to NLP tasks like sentiment analysis and text classification. By utilizing these tools, you can improve the accuracy of your NLP models and achieve better outcomes when analyzing large volumes of textual data.

Limitations and Challenges of Tokenization
Navigating tokenization faces language-specific challenges, the handling of punctuation and special characters, as well as the contextual understanding of tokens. These complexities underpin the importance of proper tokenization for downstream tasks.
Language-specific Challenges
Different languages present unique challenges in tokenization due to variations in sentence structures, word formations, and grammar rules. For instance, agglutinative languages like Korean and Turkish construct words by adding multiple morphemes together, making it difficult to identify individual tokens.
Moreover, languages with complex writing systems such as Chinese or Japanese require specialized tokenization techniques to handle the absence of spaces between words. Additionally, inflected languages like Russian or Latin pose challenges as verbs and nouns have various forms that need to be correctly represented as tokens for effective NLP tasks.
Language-specific challenges encompass a wide array of complexities that arise from the diverse nature of linguistic characteristics across different cultures and regions. Each language has its own set of rules and nuances that demand tailored approaches for accurate tokenization in NLP.
Handling Punctuation and Special Characters
When handling punctuation and special characters in tokenization, it is important to ensure that these elements are appropriately managed to maintain the integrity of the text. Punctuation marks such as commas, periods, exclamation points, and question marks should be carefully considered during tokenization.
Additionally, special characters like hashtags (#), dollar signs ($), and at symbols (@) need to be handled effectively to avoid disrupting the natural flow of language processing.
Proper management of punctuation and special characters plays a crucial role in ensuring accurate tokenization and subsequent NLP tasks.

Contextual Understanding of Tokens
Tokens, in the world of NLP, are small units like words or characters obtained through tokenization. They help machines comprehend and process text effectively. Tokenization underpins tasks such as text classification and sentiment analysis.
Challenges include handling punctuation and special characters, along with complex word structures in various languages.
Understanding tokens is crucial for effective NLP processes. For example, when processing a sentence, dividing it into smaller units helps machines analyze the meaning more accurately which leads to better results.
Importance of Proper Tokenization for Downstream Tasks
Contextualizing tokens is important as it underpins several downstream tasks in NLP. Proper tokenization ensures that the slicing of unstructured text into manageable chunks enhances various NLP operations like data tokenization and natural language processing (NLP).
It’s designed to enhance data mining, making it easier for machines to navigate complexities within the realm of text classification, sentiment analysis, and language modeling. Its significance is not merely limited to these functions but also unlocks the secrets of ever-evolving natural language understanding processes.
Therefore, ensuring proper tokenization tailored towards tackling these challenges holds paramount importance.
Conclusion – What is Tokenization in NLP?
You’ve now grasped the essence of what is tokenization in NLP – breaking down text into manageable chunks. From words to characters and subwords, you’ve explored various types of tokenization.
Delve into tools like NLTK, spaCy, and Hugging Face Tokenizers for practical application. Remember, proper tokenization is key to effective natural language processing tasks!
FAQs – What is Tokenization in NLP?
What is tokenization in Natural Language Processing (NLP)?
Tokenization in NLP is the process of breaking down text into smaller parts called tokens.
What types of tokenization are there?
There are two main types of tokenization: word and sentence. Word tokenization breaks a piece of text into individual words, while sentence tokenization divides it into sentences.
Can you give examples of how tokenization works?
Sure! In word tokenization, the sentence “I love ice cream” becomes four tokens: ‘I’, ‘love’, ‘ice’, and ‘cream’. For sentence tokenization, the paragraph “It’s sunny outside. I’ll go for a walk.” turns into two tokens: ‘It’s sunny outside.’ and ‘I’ll go for a walk.’
What tools can help with NLP Tokenization?
There are many tools available to assist with NLP Tokenisation such as NLTK, spaCy, and Hugging Face Tokenizers which all provide functions to perform both word and sentence-level tokenizations.


