Introduction
What is a Convolutional Neural Network?
Convolutional Neural Networks (CNNs) are a type of deep learning model that is especially good at analyzing visual data. If you’ve ever wondered how computers recognize images or videos, CNNs are the answer.
By mimicking how our brains process visual input, CNNs can identify patterns in images, making them the go-to tool for tasks like image classification and object detection.
In this article, I’ll break down what a convolutional neural network is, how it works, and why it’s so effective in computer vision tasks.
Key Takeaways – What is a Convolutional Neural Network?
- Understanding CNN architecture: CNNs use specific layers to process visual data, making them perfect for image analysis.
- Importance in deep learning: CNNs are central to many AI applications in fields like computer vision and medical imaging.
- Layers in CNNs: The core layers—convolutional, pooling, and fully connected—work together to detect patterns and make decisions.
- Popular applications: From facial recognition to self-driving cars, CNNs are used in various fields to solve real-world problems.
- Learning from data: CNNs can automatically learn patterns from large datasets without manual feature extraction.
Table of Contents

What is a Convolutional Neural Network (CNN)?
At its core, a convolutional neural network is a type of deep neural network specifically designed for analyzing images.
The term “convolutional” comes from the mathematical operation called convolution, which helps the network focus on important features of an image, like edges, textures, or colors. CNNs are highly effective in image-related tasks because they process data in a structured manner, analyzing small parts of an image before combining them to understand the whole picture.
What sets CNNs apart from traditional neural networks is their ability to automatically detect key features in images. You don’t need to tell the network which features to look for; it figures that out by itself as it trains.
How Does a Convolutional Neural Network Work?
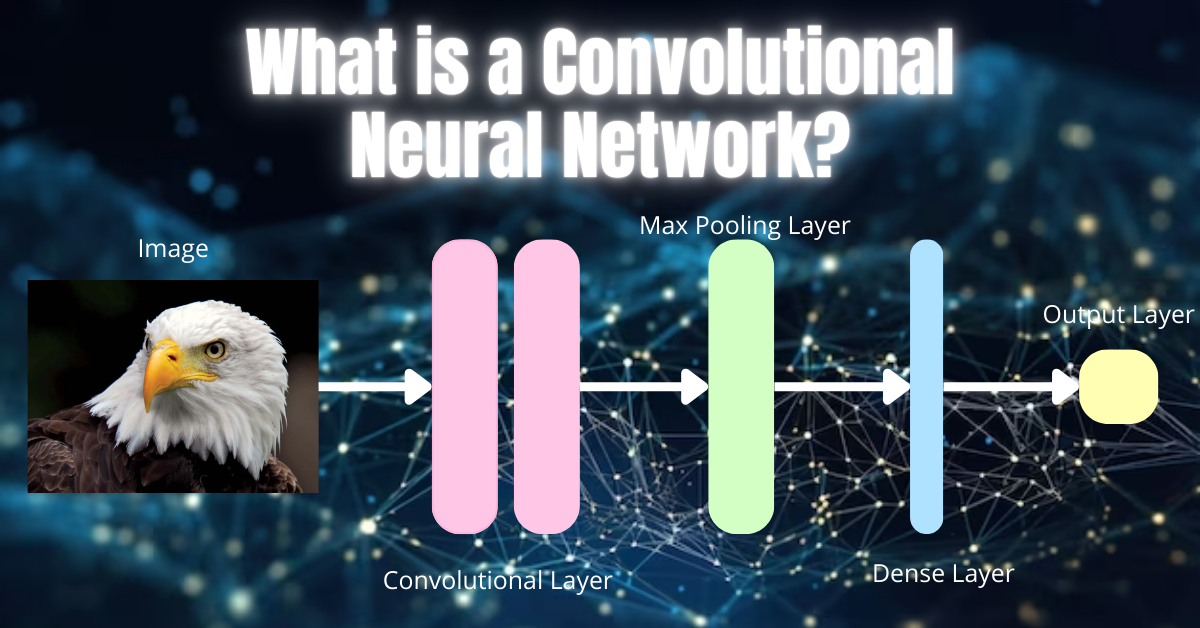
Understanding how a convolutional neural network works is key to appreciating why it’s so powerful for image-based tasks. A CNN consists of several layers, each designed to extract and process specific information from the input image.
The Convolution Operation
The first layer in a CNN applies a convolution operation to the input image. Imagine scanning through an image with a small window and detecting patterns within it—this is what convolution does. It breaks the image down into smaller pieces, then scans them for specific patterns like edges or corners. This layer learns to recognize important features that help in classifying the image.
Layers in CNN
CNNs are built with a combination of different layers that work together to analyze data:
Convolutional Layer
This is the main layer that performs the heavy lifting. It slides over the image, detecting simple features like lines and gradually identifying more complex structures. This is where the network learns to detect objects like faces or cars in an image.
Pooling Layer
The pooling layer reduces the size of the image representation, making the computation more efficient. It keeps the essential information while discarding the irrelevant data, helping the network focus on the important aspects of the image.
Fully Connected Layer
After the image is processed through the convolutional and pooling layers, it reaches the fully connected layer. This layer takes the high-level features extracted by the previous layers and uses them to classify the image or make predictions.
Activation Functions in CNNs
CNNs use activation functions like ReLU (Rectified Linear Unit) and Sigmoid to introduce non-linearity into the model. Without these functions, CNNs would struggle to model complex data. ReLU is particularly common in CNNs because it’s simple and helps avoid issues like vanishing gradients, which can occur during training.

Understanding the CNN Architecture
To fully grasp what a convolutional neural network is, you need to understand how the architecture is organized.
Input Layer
This is where the data enters the network. In the case of CNNs, the input is typically an image, but it can also be video or other types of grid-like data. Each pixel of the image is converted into numerical values that the CNN can process.
Hidden Layers
These are the layers where the magic happens. Each hidden layer extracts more complex features from the image. Early layers may detect basic elements like edges, while deeper layers combine these features to identify more abstract patterns like shapes or objects.
Output Layer
The output layer is where predictions are made. After passing through all the hidden layers, the image is classified into categories, such as “cat” or “dog,” or into more complex categories depending on the task.
Why Are CNNs Effective in Image Processing?
CNNs are highly effective at image processing because they are specifically designed to detect and recognize patterns in visual data. Here’s why CNNs work so well:
Feature Detection
One of the strengths of CNNs is their ability to detect important features in an image, such as edges, textures, and shapes. Rather than manually defining these features, CNNs learn to recognize them automatically, which is a big step forward in artificial intelligence.
Shift Invariance
A CNN can recognize an object even if it’s shifted, rotated, or resized in the image. This feature, called shift invariance, is why CNNs are so good at tasks like object detection and facial recognition.
Handling High-Dimensional Data
Images are high-dimensional data, meaning they contain a lot of information. CNNs are designed to process this data efficiently, compressing it while retaining the essential features. This makes them well-suited for tasks like image classification, where a lot of information needs to be processed quickly.

Popular Applications of Convolutional Neural Networks
CNNs are used in a wide range of real-world applications, making them an indispensable tool in fields that rely on image processing.
Image Classification
CNNs are commonly used for image classification, where the goal is to assign a label to an image. Whether it’s distinguishing between dogs and cats or identifying different types of flowers, CNNs are incredibly effective.
Object Detection and Recognition
Object detection goes a step further by not only identifying objects but also locating them in an image. This technology powers features like facial recognition on smartphones and helps self-driving cars navigate by identifying objects like pedestrians and other vehicles.
Medical Imaging
In healthcare, CNNs are used for analyzing medical images like X-rays and MRIs. They help doctors detect abnormalities such as tumors or fractures more accurately and quickly than traditional methods.
Video Processing
CNNs are not limited to static images. They can also process video data, making them useful in fields like video surveillance, where real-time object detection and activity recognition are essential.
Challenges and Limitations of Convolutional Neural Networks
While CNNs are powerful, they do come with some challenges.
Computational Power
Training a CNN requires significant computing resources. The more complex the model, the more processing power it needs. This can make training CNNs costly and time-consuming.
Data Requirements
CNNs perform best when they have access to large datasets. If the dataset is too small, the network may struggle to generalize, resulting in poor performance on unseen data.
Overfitting
Another challenge with CNNs is overfitting, where the network becomes too focused on the training data and struggles to perform well on new data. Techniques like dropout and data augmentation are used to mitigate this issue.

How to Train a CNN: A Step-by-Step Guide
Training a CNN involves several steps, from preparing the data to optimizing the model.
Data Preprocessing
Before training, you need to prepare your data. This involves resizing images, normalizing pixel values, and sometimes augmenting the data by rotating or flipping images to increase variety.
Initializing Weights
When you begin training, the CNN’s weights are set to random values. During training, the network adjusts these weights to minimize the difference between its predictions and the actual labels.
Backpropagation and Gradient Descent
The main algorithm used to train CNNs is called backpropagation. It works by calculating the error in the network’s predictions and then adjusting the weights to reduce that error. Gradient descent is the method used to optimize the weights.
Evaluating Performance
Once training is complete, you evaluate the performance of your CNN by measuring its accuracy on a separate test dataset. If the accuracy isn’t satisfactory, you can fine-tune the model by adjusting hyperparameters or using more data.
The Role of CNNs in Deep Learning
CNNs play a major role in deep learning, especially when it comes to tasks that involve visual data.
CNNs vs. Traditional Neural Networks
Traditional neural networks are not well-suited for image tasks because they don’t take spatial information into account. CNNs solve this problem by using convolution to preserve the spatial structure of the input.
CNNs and Transfer Learning
With transfer learning, you can take a pre-trained CNN and adapt it to a new task. This is useful when you don’t have enough data to train a CNN from scratch but still need a powerful model.

Evolution of CNNs: From LeNet to Modern Architectures
CNNs have evolved significantly since their introduction. The original LeNet paved the way for modern architectures.
LeNet-5
LeNet-5 was one of the first CNNs, designed to recognize handwritten digits. It laid the foundation for many of the advances in deep learning.
AlexNet, VGGNet, and ResNet
AlexNet was the first CNN to win the ImageNet competition, proving that deep learning models could outperform traditional methods. VGGNet introduced deeper networks, and ResNet solved the problem of vanishing gradients with shortcut connections.
Cutting-Edge CNN Architectures
Today, we have advanced architectures like DenseNet and EfficientNet, which push the boundaries of what CNNs can do.
FAQs – What is a Convolutional Neural Network?
What is a convolutional neural network?
A convolutional neural network (CNN) is a deep learning model that is highly effective at analyzing visual data by detecting patterns in images.
How do CNNs differ from traditional neural networks?
CNNs are specifically designed to process spatial data like images, while traditional neural networks treat all input features equally without accounting for spatial relationships.
What are the main layers in a CNN?
The main layers in a CNN are the convolutional layer, pooling layer, and fully connected layer. Each serves a different function in analyzing and classifying data.
Why are CNNs used in image processing?
CNNs are used in image processing because they automatically detect important features in an image, like edges or objects, and are efficient at handling large amounts of data.
Can CNNs be used for video analysis?
Yes, CNNs can also be used for video analysis by processing individual frames or entire sequences, making them useful for tasks like real-time object detection.
What are some popular CNN architectures?
Popular CNN architectures include AlexNet, VGGNet, and ResNet, each of which introduced innovations in how convolutional neural networks are designed and trained.
Conclusion
What is a Convolutional Neural Network?
In summary, convolutional neural networks are an essential tool in deep learning, particularly for image-related tasks. They’re effective because they automatically detect features in images, are robust in recognizing patterns, and are flexible enough to work across a wide range of applications, from healthcare to self-driving cars. If you’re looking to dive into deep learning, CNNs are the perfect starting point.
Have you used convolutional neural network?
If so, what is your experience?
I hope this blog was helpful.
Best regards 🙂